
GPT-4V是什么?怎么使用?关于OpenAI 最新GPT-4 Vision多模态的一切
GPT-4V是什么?
GPT-4V是指:视觉版的GPT-4(GPT-4 Vision),使用户能够指示GPT-4分析输入的图像,这是OpenAI正在推出的最新功能,简而言之,GPT-4V 就是可以处理图像的 GPT-4。
如何购买使用 GPT-4V 多模态技术?
OpenAI 发布的 GPT-4V多模态技术目前 10 月份以后仅对 ChatGPT Plus 用户开放,所以升级 Plus 会员后,就可以体验 GPT-4V 多模态技术了。升级的办法可以参考我们之前的文章 购买GPT-4V多模态
GPT-4V是怎么训练出来的
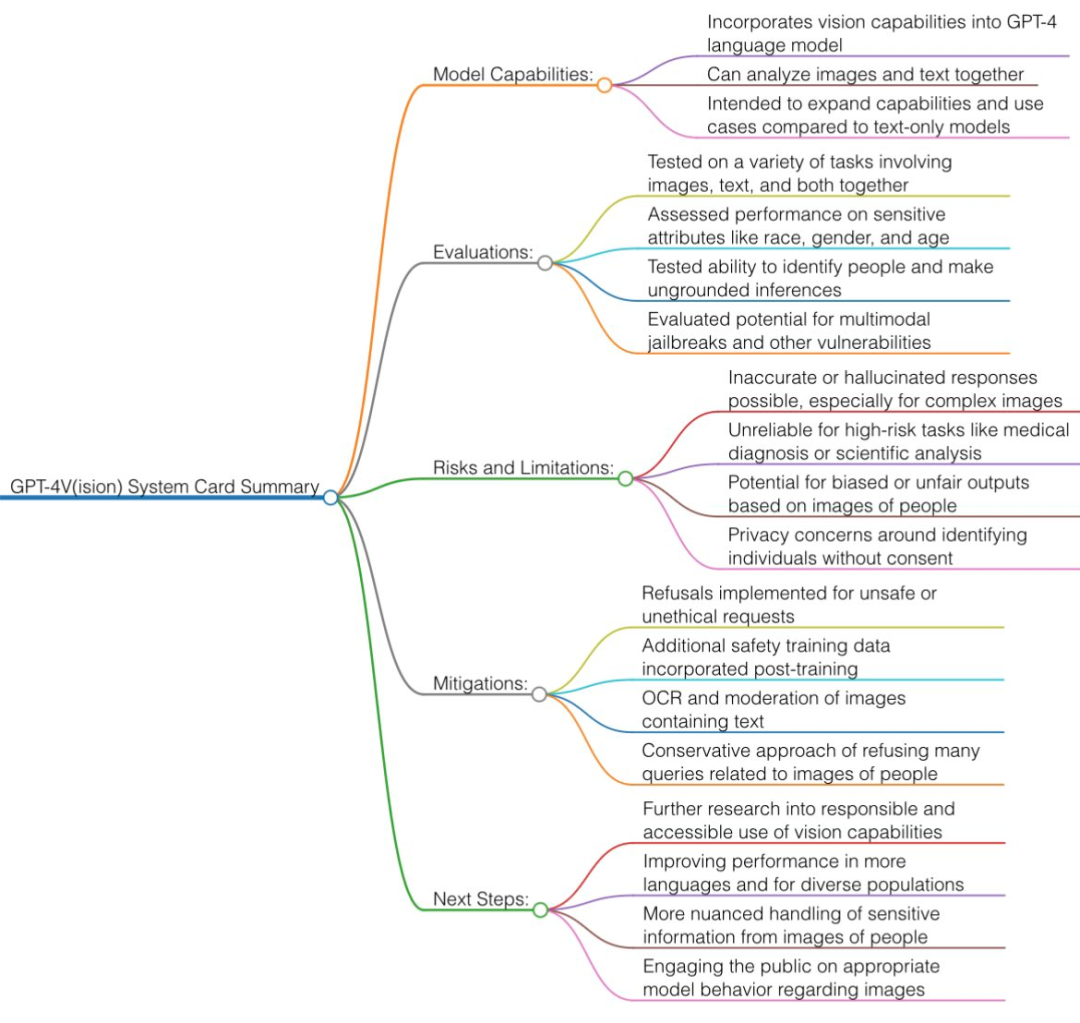
OpenAI还在今天放出了19页技术报告,解释了GPT-4V(ision)最新模型。论文地址:GPT-4V技术原理 据 OpenAI 官方介绍,GPT-4V早在2022年完成了训练,并2023年3月开始,提供了早期访问,其中包括为视障人群构建工具Be My Eyes的合作,以及1000位早期开发者alpha用户。
GPT-4V背后的技术主要还是来自GPT-4,所以训练过程是相同的。它使用了大量文本和图像数据进行预训练,然后通过RLHF进行微调。为了确保GPT-4V更加安全,OpenAI在这内测期间开展了大量对齐工作,对此进行了定性和定量评估、专家红队测试、以及缓解措施。
从 OpenAI 公布的文档中我们可以总结一下 GPT-4V 的特性:
GPT-4V 仍然是(视觉,文本)到文本模型,使用互联网图像和文本数据的混合进行训练并预测下一个单词 token,然后再用 RLHF。今天的 GPT-4V 具有比 3 月份版本更好的 OCR(从像素读取文本)能力。
安全限制:GPT-4V 在许多类别中的拒绝回答率很高。例如,当被要求回答敏感的人口统计问题、识别名人、从背景中识别地理位置以及解决验证码时,它现在会说「抱歉,我无能为力」。 一种简单的技术是将图像翻译成几个单词(例如「杀人」的刀的图片),然后应用纯文本 GPT-4 过滤器加以识别。 多模态攻击:这是一个有趣且新颖的方向。例如,你可以上传恶意提示的屏幕截图(例如 Do-Anything-Now,臭名昭著的「DAN」提示)。或者在餐巾纸上画一些神秘的符号来以某种方式停用过滤器。 在严肃的科学文献(如医学)中,GPT-4V 仍然会产生幻觉,部分原因是 OCR 不准确。所以再次强调,不要接受任何 GPT 的医疗建议!
GPT-4V的技术原理
参考同类的 AI 研究可以推测,多模态 AI 模型通常会将文本和图像转换到一个共享的编码空间,从而使它们能够通过相同的神经网络处理各种类型的数据。OpenAI 可以使用 CLIP 在视觉数据和文本数据之间架起一座桥梁,将图像和文本表征整合到同一个潜在空间(一种矢量化的数据关系网)中。这种技术可以让 ChatGPT 跨文本和图像进行上下文推理。
ChatGPT 新开放的 多模态GPT-4V 都有哪些能力?
结合所有公布的视频演示与GPT-4V System Card中的内容,手快的网友已经总结出GPT-4V的视觉能力大揭秘
目前 GPT-4V 的视觉主要能力和应用方向
物体检测:GPT-4V 能够识别并检测图像中的各种常见物体,例如汽车、动物和家居用品等。其识别能力已在标准图像数据集上进行了评估。
文本识别:此模型具备光学字符识别(OCR)技术,可在图像中发现打印或手写文字,并将其转换为机器可读的文本。这项功能在文档、标志和标题等图像中得到了验证。
人脸识别:GPT-4V 能够找出并识别图像中的人脸。它还具有一定程度的能力,可以通过面部特征来判断性别、年龄和种族属性。该模型的面部分析能力已在 FairFace 和 LFW 等数据集上进行了测试。
验证码解决方案:GPT-4V 在解决基于文本和图像的验证码时展示了视觉推理能力。这表明模型具有高级的解谜技巧。
地理定位:GPT-4V 能够识别风景图片中所呈现的城市或地理位置。这说明模型掌握了关于现实世界的知识,但也意味着存在泄露隐私的风险。
复杂图像:处理复杂的科学图表、医学扫描或具有多个重叠文本组件的图像时,该模型表现较差。它无法把握上下文细节。
GPT-4V 目前存在一些局限性
但是由于目前技术能力,GPT-4V 目前存在一些局限性:
空间关系:模型可能难以理解图像中物体的精确空间布局和位置,也可能无法正确描述物体间的相对位置。
对象重叠:当图像中的物体严重重叠时,GPT-4V 可能难以区分一个物体的结束和另一个物体的开始,导致将不同的物体混淆在一起。
背景/前景:模型不能总是准确地识别图像前景和背景中的物体。它可能会错误地描述物体之间的关系。
遮挡:如果图像中的某个物体被其他物体部分遮挡或完全遮挡,GPT-4V 可能无法识别被遮挡的物体,或者忽略与周围物体之间的关联。
细节:模型容易错过或误解图像中的微小物体、文本或复杂细节,从而导致错误地描述物体关系。
上下文推理:GPT-4V 缺乏强大的视觉推理能力,无法深入分析图像的上下文并描述物体之间的隐含关系。
置信度:模型可能会错误地描述物体之间的关系,与图像内容不符。